Bucketed Append
You can define the bucket and bucket-key to get a bucketed append table.
Example to create bucketed append table:
- Flink
CREATE TABLE my_table (
product_id BIGINT,
price DOUBLE,
sales BIGINT
) WITH (
'bucket' = '8',
'bucket-key' = 'product_id'
);
Data Skipping
The primary and most significant advantage of a bucketed append table is data skipping. When queries contain
equality (=) or IN filter conditions on the complete bucket-key, Paimon can efficiently push these predicates
down to skip irrelevant bucket files entirely. This means a large number of files that do not match the filter are
pruned before reading, drastically reducing I/O and accelerating queries.
For a composite bucket-key, the query predicate must cover all bucket-key columns with finite equality or IN
values to determine the target buckets.
For example, if bucket-key is product_id and you query:
SELECT * FROM my_table WHERE product_id = 12345;
SELECT * FROM my_table WHERE product_id IN (1, 2, 3);
Paimon will only read the bucket that contains the matching product_id values, filtering out all other bucket files.
This is extremely effective when the table has many buckets and you are querying a small subset of bucket-key values.
Bucketed Join
Bucketed table can also be used to accelerate join queries by avoiding costly shuffle operations in batch processing. For example, you can use the following Spark SQL to read a Paimon table:
SET spark.sql.sources.v2.bucketing.enabled = true;
CREATE TABLE FACT_TABLE (order_id INT, f1 STRING) TBLPROPERTIES ('bucket'='10', 'bucket-key' = 'order_id');
CREATE TABLE DIM_TABLE (order_id INT, f2 STRING) TBLPROPERTIES ('bucket'='10', 'primary-key' = 'order_id');
SELECT * FROM FACT_TABLE JOIN DIM_TABLE on t1.order_id = t4.order_id;
The spark.sql.sources.v2.bucketing.enabled config is used to enable bucketing for V2 data sources. When turned on,
Spark will recognize the specific distribution reported by a V2 data source through SupportsReportPartitioning, and
will try to avoid shuffle if necessary.
The costly join shuffle will be avoided if two tables have the same bucketing strategy and same number of buckets.
Bucketed Streaming
An ordinary Append table has no strict ordering guarantees for its streaming writes and reads, but there are some cases where you need to define a key similar to Kafka's.
Every record in the same bucket is ordered strictly, streaming read will transfer the record to down-stream exactly in the order of writing. To use this mode, you do not need to config special configurations, all the data will go into one bucket as a queue.
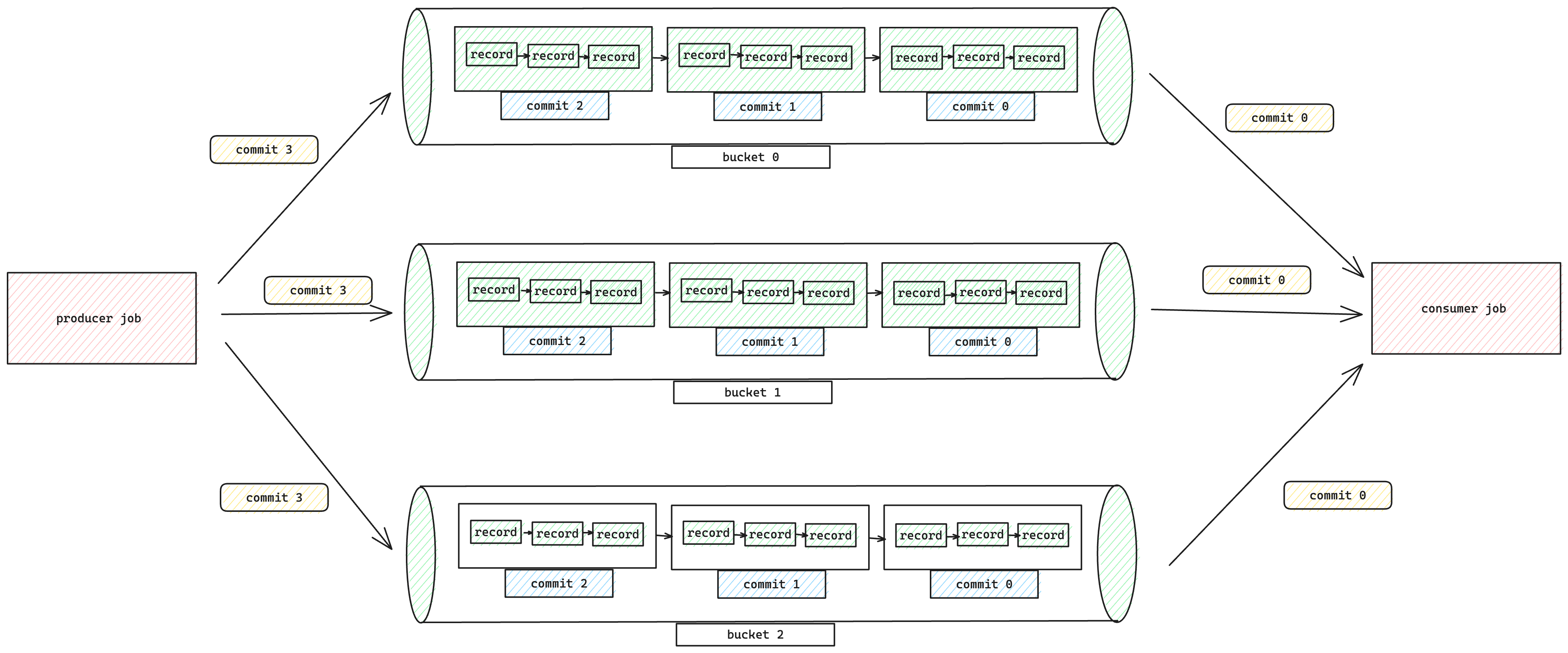
Streaming Read Order
For streaming reads, records are produced in the following order:
- For any two records from two different partitions
- If
scan.plan-sort-partitionis set to true, the record with a smaller partition value will be produced first. - Otherwise, the record with an earlier partition creation time will be produced first.
- If
- For any two records from the same partition and the same bucket, the first written record will be produced first.
- For any two records from the same partition but two different buckets, different buckets are processed by different tasks, there is no order guarantee between them.
Watermark Definition
You can define watermark for reading Paimon tables:
CREATE TABLE t (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (...);
-- launch a bounded streaming job to read paimon_table
SELECT window_start, window_end, COUNT(`user`) FROM TABLE(
TUMBLE(TABLE t, DESCRIPTOR(order_time), INTERVAL '10' MINUTES)) GROUP BY window_start, window_end;
You can also enable Flink Watermark alignment, which will make sure no sources/splits/shards/partitions increase their watermarks too far ahead of the rest:
| Key | Default | Type | Description |
|---|---|---|---|
scan.watermark.alignment.group | (none) | String | A group of sources to align watermarks. |
scan.watermark.alignment.max-drift | (none) | Duration | Maximal drift to align watermarks, before we pause consuming from the source/task/partition. |
Bounded Stream
Streaming Source can also be bounded, you can specify 'scan.bounded.watermark' to define the end condition for bounded streaming mode, stream reading will end until a larger watermark snapshot is encountered.
Watermark in snapshot is generated by writer, for example, you can specify a kafka source and declare the definition of watermark. When using this kafka source to write to Paimon table, the snapshots of Paimon table will generate the corresponding watermark, so that you can use the feature of bounded watermark when streaming reads of this Paimon table.
CREATE TABLE kafka_table (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH ('connector' = 'kafka'...);
-- launch a streaming insert job
INSERT INTO paimon_table SELECT * FROM kakfa_table;
-- launch a bounded streaming job to read paimon_table
SELECT * FROM paimon_table /*+ OPTIONS('scan.bounded.watermark'='...') */;