Basic Concepts
File Layouts
All files of a table are stored under one base directory. Paimon files are organized in a layered style. The following image illustrates the file layout. Starting from a snapshot file, Paimon readers can recursively access all records from the table.
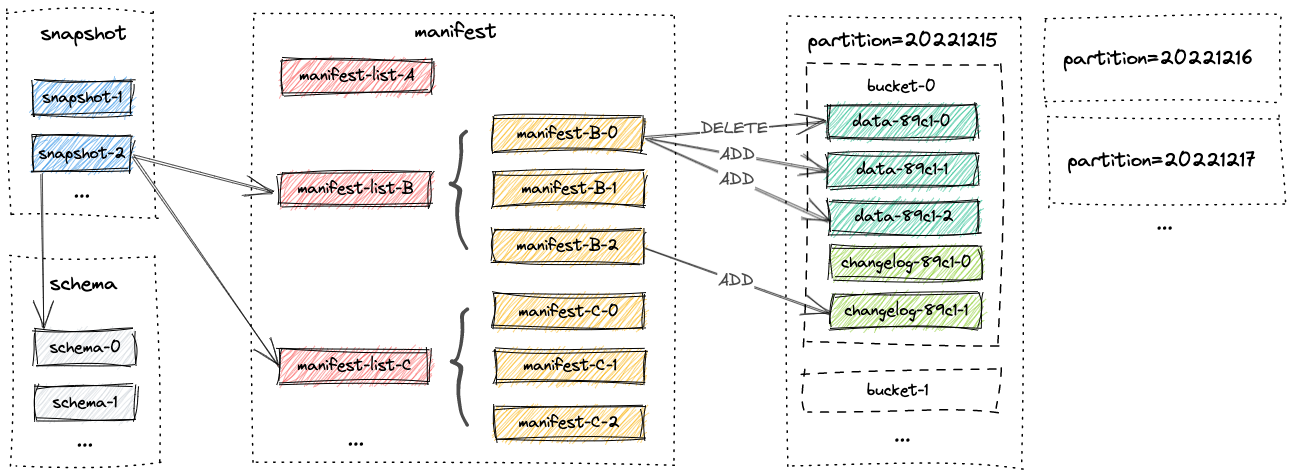
Snapshot
All snapshot files are stored in the snapshot directory.
A snapshot file is a JSON file containing information about this snapshot, including
- the schema file in use
- the manifest list containing all changes of this snapshot
A snapshot captures the state of a table at some point in time. Users can access the latest data of a table through the latest snapshot. By time traveling, users can also access the previous state of a table through an earlier snapshot.
Manifest Files
All manifest lists and manifest files are stored in the manifest directory.
A manifest list is a list of manifest file names.
A manifest file is a file containing changes about LSM data files and changelog files. For example, which LSM data file is created and which file is deleted in the corresponding snapshot.
Data Files
Data files are grouped by partitions. Currently, Paimon supports using parquet (default), orc and avro as data file's format.
Partition
Paimon adopts the same partitioning concept as Apache Hive to separate data.
Partitioning is an optional way of dividing a table into related parts based on the values of particular columns like date, city, and department. Each table can have one or more partition keys to identify a particular partition.
By partitioning, users can efficiently operate on a slice of records in the table.
Consistency Guarantees
Paimon writers use two-phase commit protocol to atomically commit a batch of records to the table. Each commit produces at most two snapshots at commit time. It depends on the incremental write and compaction strategy. If only incremental writes are performed without triggering a compaction operation, only an incremental snapshot will be created. If a compaction operation is triggered, an incremental snapshot and a compacted snapshot will be created.
For any two writers modifying a table at the same time, as long as they do not modify the same partition, their commits can occur in parallel. If they modify the same partition, only snapshot isolation is guaranteed. That is, the final table state may be a mix of the two commits, but no changes are lost. See dedicated compaction job for more info.