Concurrency Control
Paimon supports optimistic concurrency for multiple concurrent write jobs.
Each job writes data at its own pace and generates a new snapshot based on the current snapshot by applying incremental files (deleting or adding files) at the time of committing.
There may be two types of commit failures here:
- Snapshot conflict: the snapshot id has been preempted, the table has generated a new snapshot from another job. OK, let's commit again.
- Files conflict: The file that this job wants to delete has been deleted by another jobs. At this point, the job can only fail. (For streaming jobs, it will fail and restart, intentionally failover once)
Snapshot conflict
Paimon's snapshot ID is unique, so as long as the job writes its snapshot file to the file system, it is considered successful.
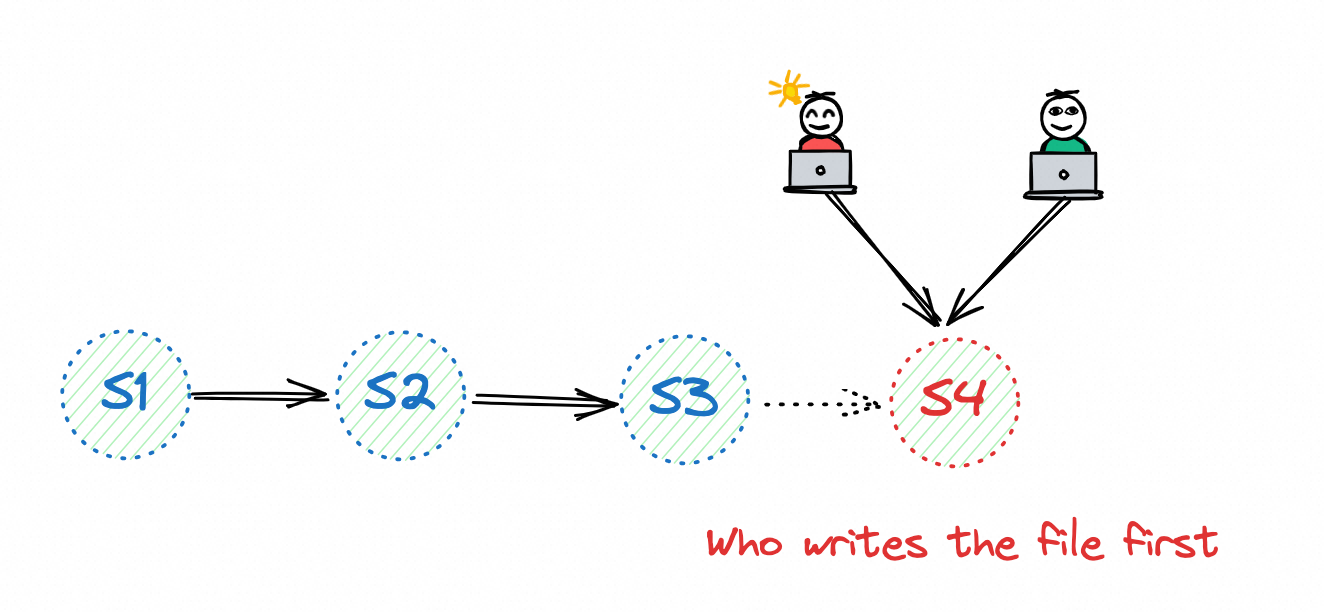
Paimon uses the file system's renaming mechanism to commit snapshots, which is secure for HDFS as it ensures transactional and atomic renaming.
But for object storage such as OSS and S3, their 'RENAME' does not have atomic semantic. We need to configure Hive or
jdbc metastore and enable 'lock.enabled' option for the catalog. Otherwise, there may be a chance of losing the snapshot.
Files conflict
When Paimon commits a file deletion (which is only a logical deletion), it checks for conflicts with the latest snapshot. If there are conflicts (which means the file has been logically deleted), it can no longer continue on this commit node, so it can only intentionally trigger a failover to restart, and the job will retrieve the latest status from the filesystem in the hope of resolving this conflict.
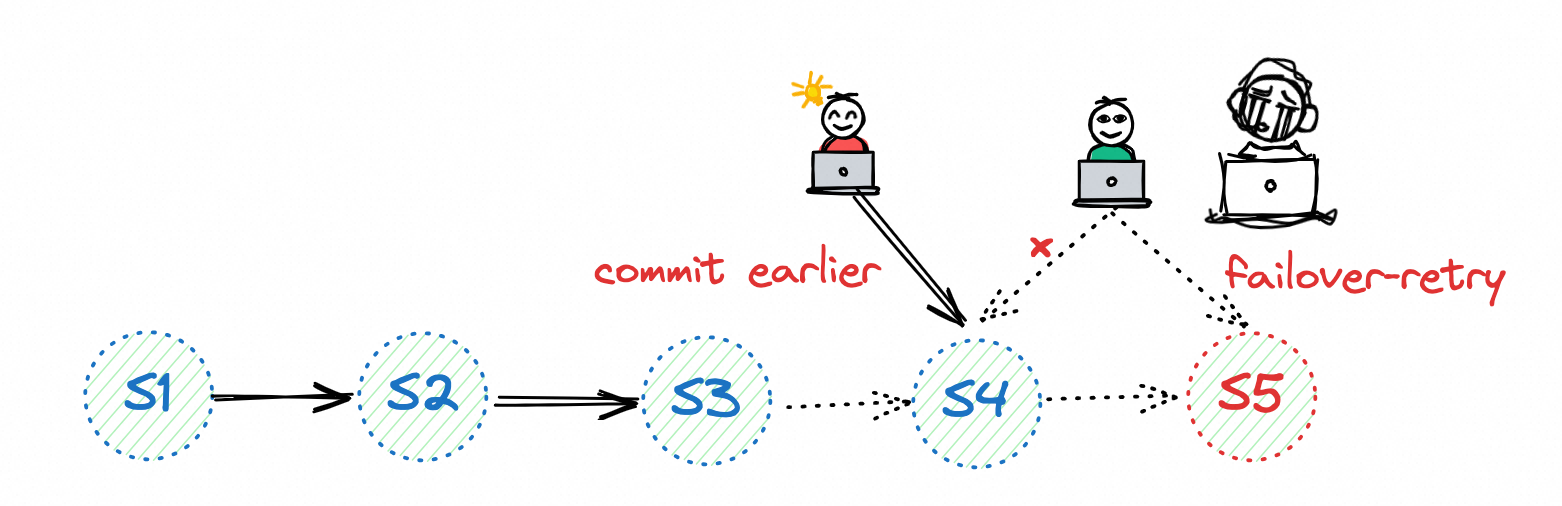
Paimon will ensure that there is no data loss or duplication here, but if two streaming jobs are writing at the same time and there are conflicts, you will see that they are constantly restarting, which is not a good thing.
The essence of conflict lies in deleting files (logically), and deleting files is born from compaction, so as long as we close the compaction of the writing job (Set 'write-only' to true) and start a separate job to do the compaction work, everything is very good.
See dedicated compaction job for more info.