Dedicated Compaction
Paimon's snapshot management supports writing with multiple writers.
For S3-like object store, its 'RENAME' does not have atomic semantic. We need to configure Hive metastore and
enable 'lock.enabled' option for the catalog.
By default, Paimon supports concurrent writing to different partitions. A recommended mode is that streaming job writes records to Paimon's latest partition, Simultaneously batch job (overwrite) writes records to the historical partition.
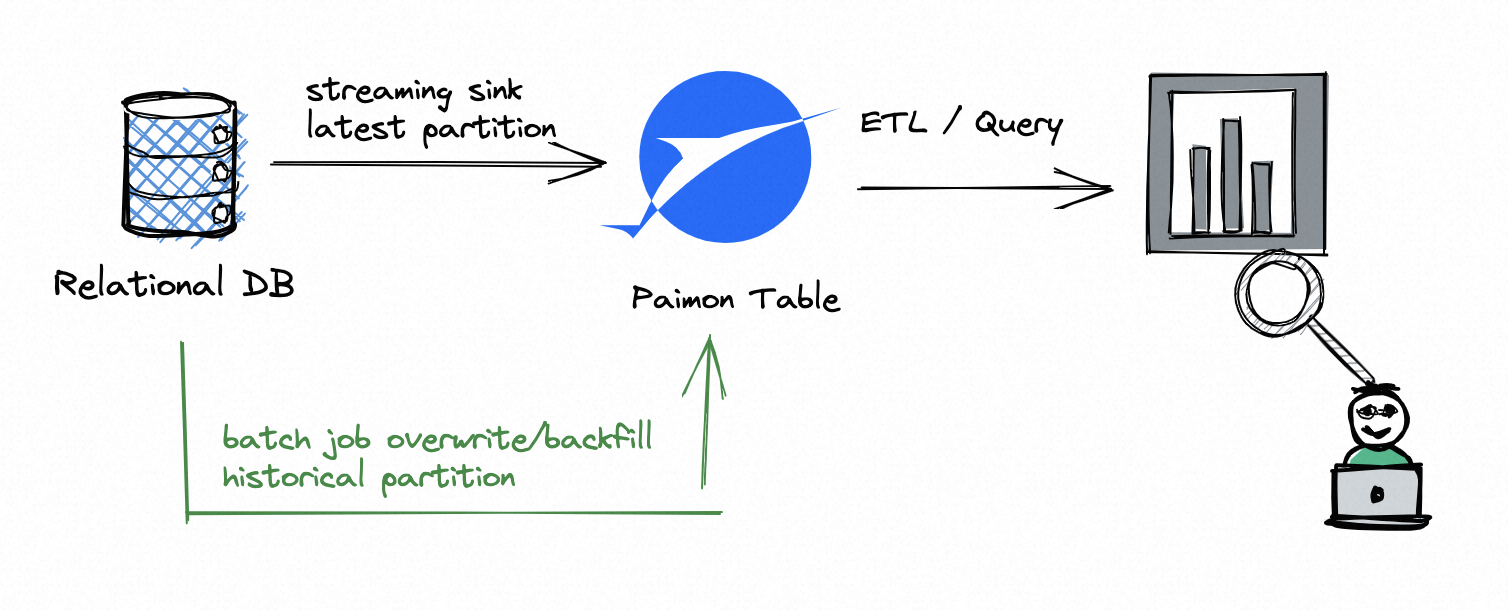
So far, everything works very well, but if you need multiple writers to write records to the same partition, it will
be a bit more complicated. For example, you don't want to use UNION ALL, you have multiple
streaming jobs to write records to a 'partial-update' table. Please refer to the 'Dedicated Compaction Job' below.
Dedicated Compaction Job
By default, Paimon writers will perform compaction as needed during writing records. This is sufficient for most use cases.
Compaction will mark some data files as "deleted" (not really deleted, see expiring snapshots for more info). If multiple writers mark the same file, a conflict will occur when committing the changes. Paimon will automatically resolve the conflict, but this may result in job restarts.
To avoid these downsides, users can also choose to skip compactions in writers, and run a dedicated job only for compaction. As compactions are performed only by the dedicated job, writers can continuously write records without pausing and no conflicts will ever occur.
To skip compactions in writers, set the following table property to true.
| Option | Required | Default | Type | Description |
|---|---|---|---|---|
write-only | No | false | Boolean | If set to true, compactions and snapshot expiration will be skipped. This option is used along with dedicated compact jobs. |
To run a dedicated job for compaction, follow these instructions.
- Flink SQL
- Flink Action Jar
Run the following sql:
CALL sys.compact(
`table` => 'default.T',
partitions => 'p=0',
options => 'sink.parallelism=4',
`where` => 'dt>10 and h<20'
);
Run the following command to submit a compaction job for the table.
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-1.5-SNAPSHOT.jar \
compact \
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
[--partition <partition-name>] \
[--compact_strategy <minor / full>] \
[--table_conf <table_conf>] \
[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]
Example: compact table
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-1.5-SNAPSHOT.jar \
compact \
--warehouse s3:///path/to/warehouse \
--database test_db \
--table test_table \
--partition dt=20221126,hh=08 \
--partition dt=20221127,hh=09 \
--table_conf sink.parallelism=10 \
--compact_strategy minor \
--catalog_conf s3.endpoint=https://****.com \
--catalog_conf s3.access-key=***** \
--catalog_conf s3.secret-key=*****
--compact_strategyDetermines how to pick files to be merged, the default is determined by the runtime execution mode, streaming-mode useminorstrategy and batch-mode usefullstrategy.full: Only supports batch mode. All files will be selected for merging.minor: Pick the set of files that need to be merged based on specified conditions.
You can use -D execution.runtime-mode=batch or -yD execution.runtime-mode=batch (for the ON-YARN scenario) to control batch or streaming mode. If you submit a batch job, all
current table files will be compacted. If you submit a streaming job, the job will continuously monitor new changes
to the table and perform compactions as needed.
For more usage of the compact action, see
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-1.5-SNAPSHOT.jar \
compact --help
Similarly, the default is synchronous compaction, which may cause checkpoint timeouts.
You can configure table_conf to use Asynchronous Compaction.
Database Compaction Job
You can run the following command to submit a compaction job for multiple database.
- Flink SQL
- Flink Action Jar
Run the following sql:
CALL sys.compact_database(
including_databases => 'includingDatabases',
mode => 'mode',
including_tables => 'includingTables',
excluding_tables => 'excludingTables',
table_options => 'tableOptions'
)
-- example
CALL sys.compact_database(
including_databases => 'db1|db2',
mode => 'combined',
including_tables => 'table_.*',
excluding_tables => 'ignore',
table_options => 'sink.parallelism=4'
)
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-1.5-SNAPSHOT.jar \
compact_database \
--warehouse <warehouse-path> \
--including_databases <database-name|name-regular-expr> \
[--including_tables <paimon-table-name|name-regular-expr>] \
[--excluding_tables <paimon-table-name|name-regular-expr>] \
[--mode <compact-mode>] \
[--compact_strategy <minor / full>] \
[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \
[--table_conf <paimon-table_conf> [--table_conf <paimon-table_conf> ...]]
--including_databasesis used to specify which database is to be compacted. In compact mode, you need to specify a database name, in compact_database mode, you could specify multiple database, regular expression is supported.--including_tablesis used to specify which source tables are to be compacted, you must use '|' to separate multiple tables, the format isdatabaseName.tableName, regular expression is supported. For example, specifying "--including_tables db1.t1|db2.+" means to compact table 'db1.t1' and all tables in the db2 database.--excluding_tablesis used to specify which source tables are not to be compacted. The usage is same as "--including_tables". "--excluding_tables" has higher priority than "--including_tables" if you specified both.--modeis used to specify compaction mode. Possible values:- "divided" (the default mode if you haven't specified one): start a sink for each table, the compaction of the new table requires restarting the job.
- "combined": start a single combined sink for all tables, the new table will be automatically compacted.
--catalog_confis the configuration for Paimon catalog. Each configuration should be specified in the formatkey=value. See here for a complete list of catalog configurations.--table_confis the configuration for compaction. Each configuration should be specified in the formatkey=value. Pivotal configuration is listed below:
| Key | Default | Type | Description |
|---|---|---|---|
| continuous.discovery-interval | 10 s | Duration | The discovery interval of continuous reading. |
| sink.parallelism | (none) | Integer | Defines a custom parallelism for the sink. By default, if this option is not defined, the planner will derive the parallelism for each statement individually by also considering the global configuration. |
You can use -D execution.runtime-mode=batch to control batch or streaming mode. If you submit a batch job, all
current table files will be compacted. If you submit a streaming job, the job will continuously monitor new changes
to the table and perform compactions as needed.
If you only want to submit the compaction job and don't want to wait until the job is done, you should submit in detached mode.
You can set --mode combined to enable compacting newly added tables without restarting job.
Example1: compact database
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-1.5-SNAPSHOT.jar \
compact_database \
--warehouse s3:///path/to/warehouse \
--including_databases test_db \
--catalog_conf s3.endpoint=https://****.com \
--catalog_conf s3.access-key=***** \
--catalog_conf s3.secret-key=*****
Example2: compact database in combined mode
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-1.5-SNAPSHOT.jar \
compact_database \
--warehouse s3:///path/to/warehouse \
--including_databases test_db \
--mode combined \
--catalog_conf s3.endpoint=https://****.com \
--catalog_conf s3.access-key=***** \
--catalog_conf s3.secret-key=***** \
--table_conf continuous.discovery-interval=*****
For more usage of the compact_database action, see
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-1.5-SNAPSHOT.jar \
compact_database --help
Sort Compact
If your table is configured with dynamic bucket primary key table or append table , you can trigger a compact with specified column sort to speed up queries.
- Flink SQL
- Flink Action Jar
Run the following sql:
-- sort compact table
CALL sys.compact(`table` => 'default.T', order_strategy => 'zorder', order_by => 'a,b')
<FLINK_HOME>/bin/flink run \
-D execution.runtime-mode=batch \
/path/to/paimon-flink-action-1.5-SNAPSHOT.jar \
compact \
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
--order_strategy <orderType> \
--order_by <col1,col2,...> \
[--partition <partition-name>] \
[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \
[--table_conf <paimon-table-dynamic-conf> [--table_conf <paimon-table-dynamic-conf>] ...]
There are two new configuration in Sort Compact
| Configuration | Description |
|---|---|
--order_strategy |
the order strategy now support "zorder" and "hilbert" and "order". For example: --order_strategy zorder |
--order_by |
Specify the order columns. For example: --order_by col0, col1 |
The sort parallelism is the same as the sink parallelism, you can dynamically specify it by add conf --table_conf sink.parallelism=<value>.
Sort Compact currently supports only bucket=-1 and batch mode.
Historical Partition Compact
You can run the following command to submit a compaction job for partition which has not received any new data for a period of time. Small files in those partitions will be full compacted.
This feature now is only used in batch mode.
For Table
This is for one table.
- Flink SQL
- Flink Action Jar
Run the following sql:
-- history partition compact table
CALL sys.compact(`table` => 'default.T', partition_idle_time => '1 d')
<FLINK_HOME>/bin/flink run \
-D execution.runtime-mode=batch \
/path/to/paimon-flink-action-1.5-SNAPSHOT.jar \
compact \
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
--partition_idle_time <partition-idle-time> \
[--partition <partition-name>] \
[--compact_strategy <minor / full>] \
[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \
[--table_conf <paimon-table-dynamic-conf> [--table_conf <paimon-table-dynamic-conf>] ...]
There are one new configuration in Historical Partition Compact
--partition_idle_time: this is used to do a full compaction for partition which had not received any new data for 'partition_idle_time'. And only these partitions will be compacted.
For Databases
This is for multiple tables in different databases.
- Flink SQL
- Flink Action Jar
Run the following sql:
-- history partition compact table
CALL sys.compact_database(
including_databases => 'includingDatabases',
mode => 'mode',
including_tables => 'includingTables',
excluding_tables => 'excludingTables',
table_options => 'tableOptions',
partition_idle_time => 'partition_idle_time'
);
Example: compact historical partitions for tables in database
-- history partition compact table
CALL sys.compact_database(
includingDatabases => 'test_db',
mode => 'combined',
partition_idle_time => '1 d'
);
<FLINK_HOME>/bin/flink run \
-D execution.runtime-mode=batch \
/path/to/paimon-flink-action-1.5-SNAPSHOT.jar \
compact_database \
--warehouse <warehouse-path> \
--including_databases <database-name|name-regular-expr> \
--partition_idle_time <partition-idle-time> \
[--including_tables <paimon-table-name|name-regular-expr>] \
[--excluding_tables <paimon-table-name|name-regular-expr>] \
[--mode <compact-mode>] \
[--compact_strategy <minor / full>] \
[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \
[--table_conf <paimon-table_conf> [--table_conf <paimon-table_conf> ...]]
Example: compact historical partitions for tables in database
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-1.5-SNAPSHOT.jar \
compact_database \
--warehouse s3:///path/to/warehouse \
--including_databases test_db \
--partition_idle_time 1d \
--catalog_conf s3.endpoint=https://****.com \
--catalog_conf s3.access-key=***** \
--catalog_conf s3.secret-key=*****