This documentation is for an unreleased version of Apache Paimon. We recommend you use the latest stable version.
Data Evolution
Data Evolution #
Overview #
Paimon supports complete Schema Evolution, allowing you to freely add, modify, or delete column schema. But how to backfill newly added columns or update column data.
Data Evolution Mode is a new feature for Append tables that revolutionizes how you handle data evolution, particularly when adding new columns. This mode allows you to update partial columns without rewriting entire data files. Instead, it writes new column data to separate files and intelligently merges them with the original data during read operations.
The data evolution mode offers significant advantages for your data lake architecture:
-
Efficient Partial Column Updates: With this mode, you can use Spark’s MERGE INTO statement to update a subset of columns. This avoids the high I/O cost of rewriting the whole file, as only the updated columns are written.
-
Reduced File Rewrites: In scenarios with frequent schema changes, such as adding new columns, the traditional method requires constant file rewriting. Data evolution mode eliminates this overhead by appending new column data to dedicated files. This approach is much more efficient and reduces the burden on your storage system.
-
Optimized Read Performance: The new mode is designed for seamless data retrieval. During query execution, Paimon’s engine efficiently combines the original data with the new column data, ensuring that read performance remains uncompromised. The merge process is highly optimized, so your queries run just as fast as they would on a single, consolidated file.
To enable data evolution, you must enable row-tracking and set the row-tracking.enabled and data-evolution.enabled property to true when creating an append table. This ensures that the table is ready for efficient schema evolution operations.
Use Spark Sql as an example:
CREATE TABLE target_table (id INT, b INT, c INT) TBLPROPERTIES (
'row-tracking.enabled' = 'true',
'data-evolution.enabled' = 'true'
);
INSERT INTO target_table VALUES (1, 1, 1), (2, 2, 2);
Now we could update partial columns by spark ‘MERGE INTO’ statement or flink ‘data_evolution_merge_into’ procedure:
Spark #
CREATE TABLE source_table (id INT, b INT);
INSERT INTO source_table VALUES (1, 11), (2, 22), (3, 33);
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN MATCHED THEN UPDATE SET t.b = s.b
WHEN NOT MATCHED THEN INSERT (id, b, c) VALUES (id, b, 0);
SELECT * FROM target_table;
+----+----+----+
| id | b | c |
+----+----+----+
| 1 | 11 | 1 |
| 2 | 22 | 2 |
| 3 | 33 | 0 |
This statement updates only the b column in the target table target_table based on the matching records from the source table
source_table. The id column and c column remain unchanged, and new records are inserted with the specified values. The difference between this and table those are not enabled with data evolution is that only the b column data is written to new files.
Note that:
- Data Evolution Table does not support ‘Delete’, ‘Update’, or ‘Compact’ statement yet.
- Merge Into for Data Evolution Table does not support ‘WHEN NOT MATCHED BY SOURCE’ clause.
Flink #
Since Flink does not currently support the MERGE INTO syntax, we simulate the merge-into process using the data_evolution_merge_into procedure, as shown below:
CREATE TABLE source_table (id INT, b INT);
INSERT INTO source_table VALUES (1, 11), (2, 22), (3, 33);
CALL sys.data_evolution_merge_into(
'my_db.target_table',
'', /* Optional target alias */
'', /* Optional source sqls */
'source_table',
'source_table.id=target_table.id',
'b=source_table.b',
2 /* Specify sink parallelism */
);
SELECT * FROM source_table
+----+----+----+
| id | b | c |
+----+----+----+
| 1 | 11 | 1 |
| 2 | 22 | 2 |
Note that:
- Compared to Spark implementation, Flink data_evolution_merge_into procedure only supports updating/inserting new columns now. Inserting new rows is not supported yet.
Self Merge #
Self-merge refers to the case where the source and target of the merge operation are the same table. This is useful when you want to transform existing column values in place — for example, applying a UDF to rewrite a column.
Since the source table cannot be the same as the target table directly, you need to create a temporary view based on
the system table T$row_tracking (which exposes the hidden _ROW_ID column) and use _ROW_ID as the merge condition.
-- 1. Register a UDF
CREATE TEMPORARY FUNCTION concat_string AS 'com.example.StringConcatUdf';
-- 2. Create a view from the row-tracking system table
CREATE TEMPORARY VIEW source_view AS
SELECT _ROW_ID, concat_string(name) AS name
FROM my_db.target_table$row_tracking;
-- 3. Self-merge: update the name column using the UDF result
CALL sys.data_evolution_merge_into(
'my_db.target_table',
'TempT',
-- alternatively, you could also pass the create sqls in procedure directly
-- like: 'CREATE TEMPORARY FUNCTION concat_string AS ''com.example.StringConcatUdf''; CREATE TEMPORARY VIEW XXX'
'',
'source_view',
'TempT._ROW_ID=source_view._ROW_ID',
'name=source_view.name',
2
);
Note that:
- The source and target table name cannot be the same. You must create a temporary view as the source.
- use
view._ROW_ID=source._ROW_IDto identify the self-merge pattern. _ROW_IDis only available via the$row_trackingsystem table.- Self-merge only supports
WHEN MATCHED THEN UPDATEsemantics.
File Group Spec #
Through the RowId metadata, files are organized into a file group.
When writing: MERGE INTO clause for Data Evolution Table only updates the specified columns, and writes the updated column data to new files. The original data files remain unchanged.
When reading: Paimon reads both the original data files and the new files containing the updated column data. It then merges the data from these two sources to present a unified view of the table. This merging process is optimized to ensure that read performance is not significantly impacted.
After writing, the files in target_table like below:
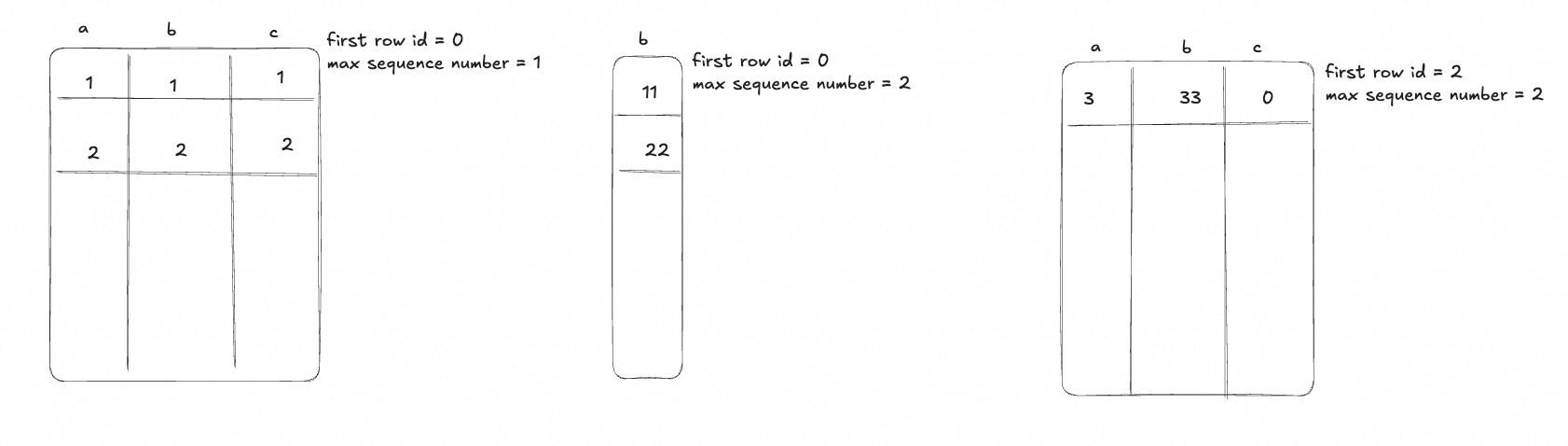
When reading, the files with the same first row id will merge fields.
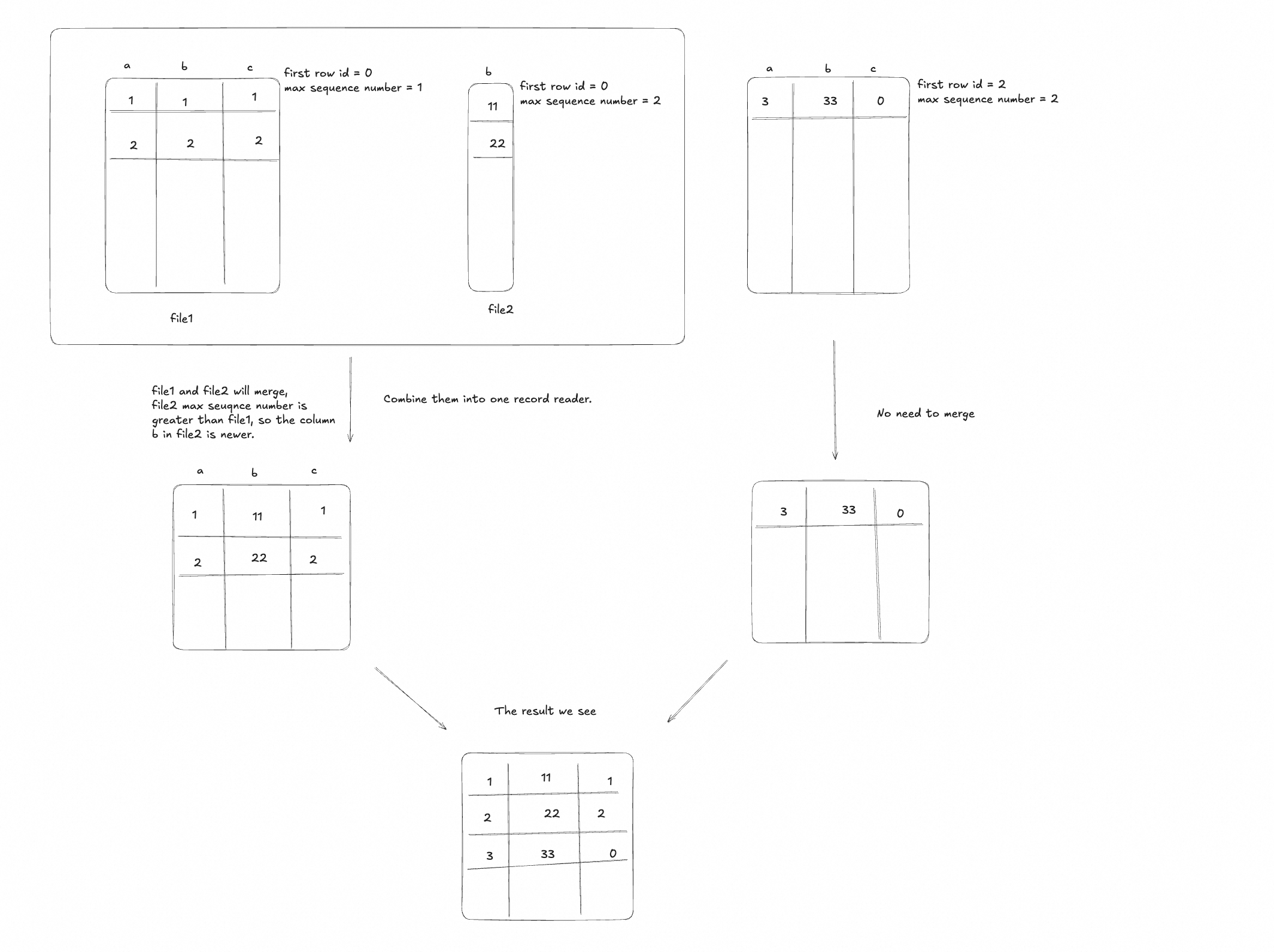
The advantage to the mode is:
- Avoid rewriting the whole file when updating partial columns, reducing I/O cost.
- The read performance is not significantly impacted, as the merge process is optimized.
- The disk space is used more efficiently, as only the updated columns are written to new files.