Apache Amoro With Paimon
Apache Amoro(incubating) is a Lakehouse management system built on open data lake formats. Working with compute engines including Flink, Spark, and Trino, Amoro brings pluggable and Table Maintenance features for a Lakehouse to provide out-of-the-box data warehouse experience, and helps data platforms or products easily build infra-decoupled, stream-and-batch-fused and lake-native architecture. AMS(Amoro Management Service) provides Lakehouse management features, like self-optimizing, data expiration, etc. It also provides a unified catalog service for all compute engines, which can also be combined with existing metadata services like HMS(Hive Metastore).
Table Format
Apache Amoro supports all catalog types supported by paimon, including common catalog: Hadoop, Hive, Glue, JDBC, Nessie and other third-party catalog. Amoro supports all storage types supported by Paimon, including common store: Hadoop, S3, GCS, ECS, OSS, and so on.
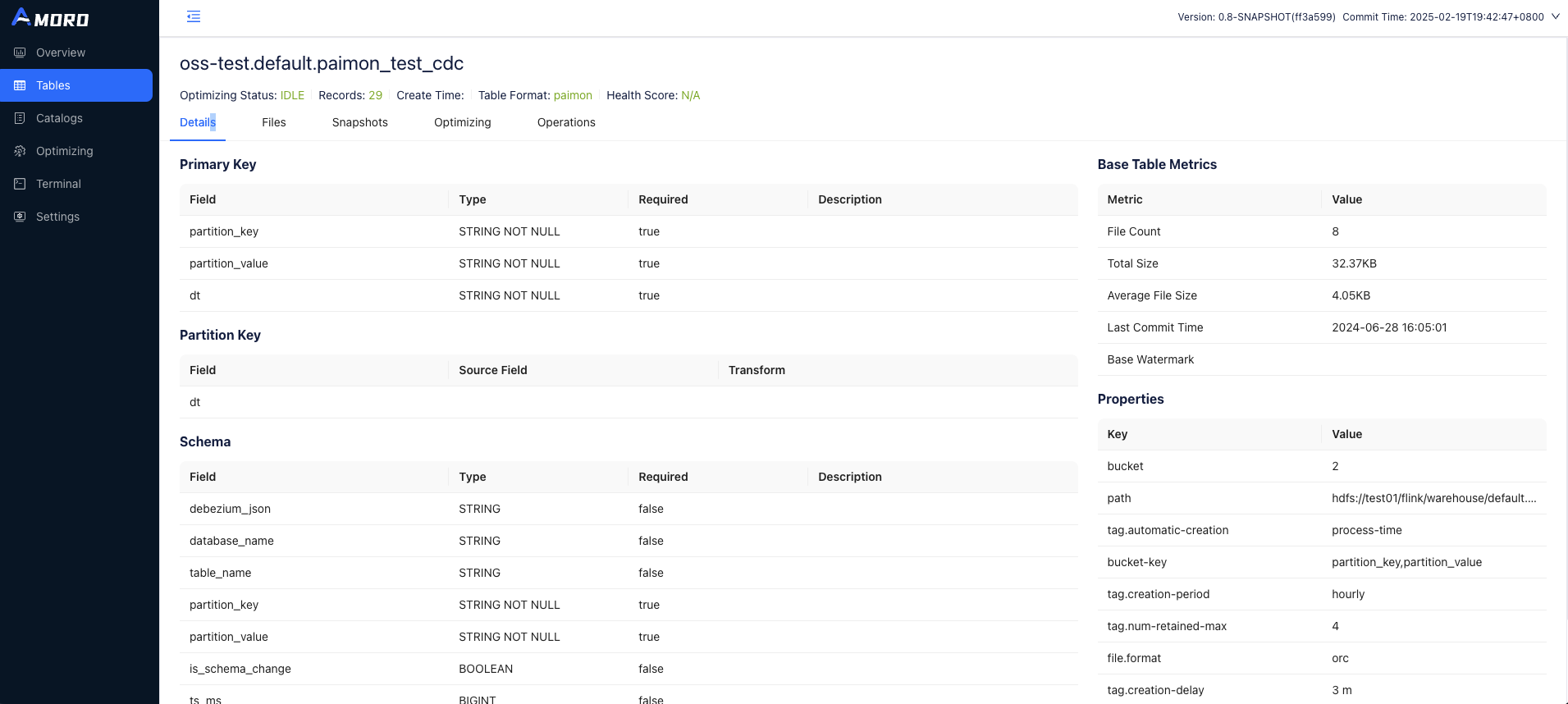
In the future, Paimon automatic optimization strategy will be supported, and users can achieve the best balance experience by cooperating with Amoro automatic optimization