Table Mode
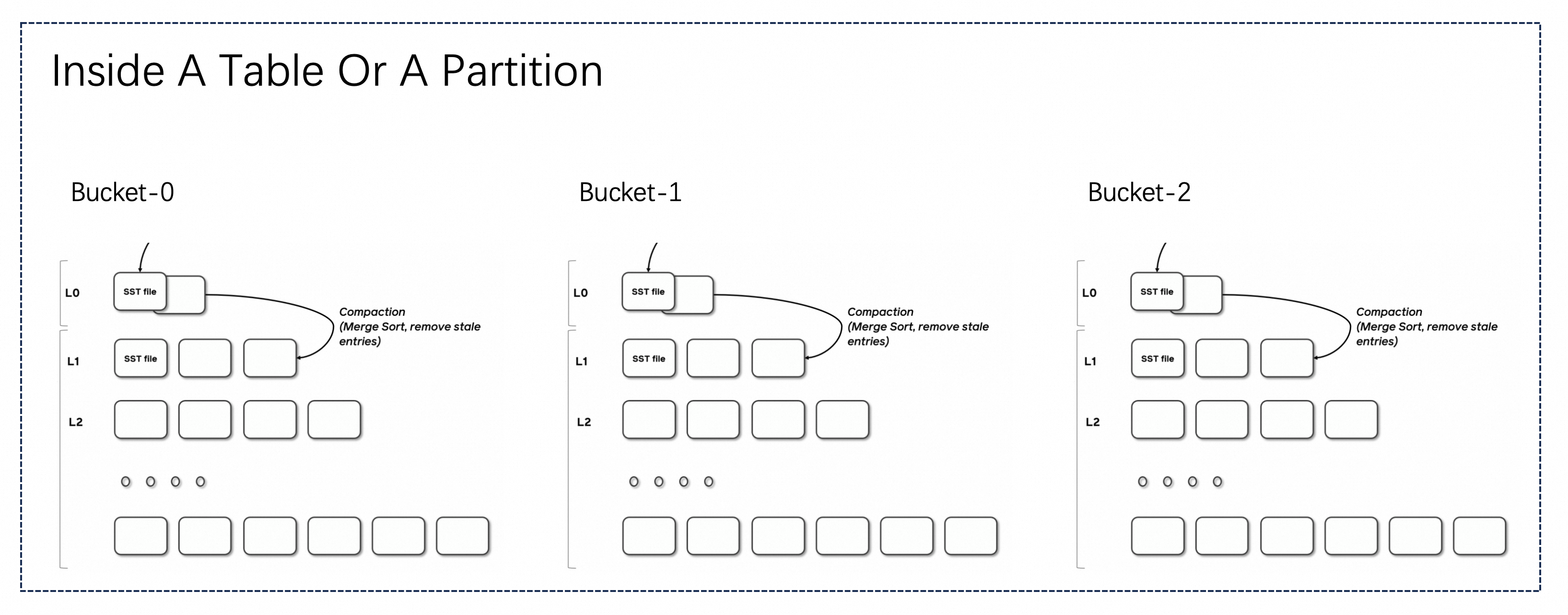
The file structure of the primary key table is roughly shown in the above figure. The table or partition contains multiple buckets, and each bucket is a separate LSM tree structure that contains multiple files.
The writing process of LSM is roughly as follows: Flink checkpoint flush L0 files, and trigger a compaction as needed to merge the data. According to the different processing ways during writing, there are three modes:
- MOR (Merge On Read): Default mode, only minor compactions are performed, and merging are required for reading.
- COW (Copy On Write): Using
'full-compaction.delta-commits' = '1', full compaction will be synchronized, which means the merge is completed on write. - MOW (Merge On Write): Using
'deletion-vectors.enabled' = 'true', in writing phase, LSM will be queried to generate the deletion vector file for the data file, which directly filters out unnecessary lines during reading.
The Merge On Write mode is recommended for general primary key tables (merge-engine is default deduplicate).
Merge On Read
MOR is the default mode of primary key table.
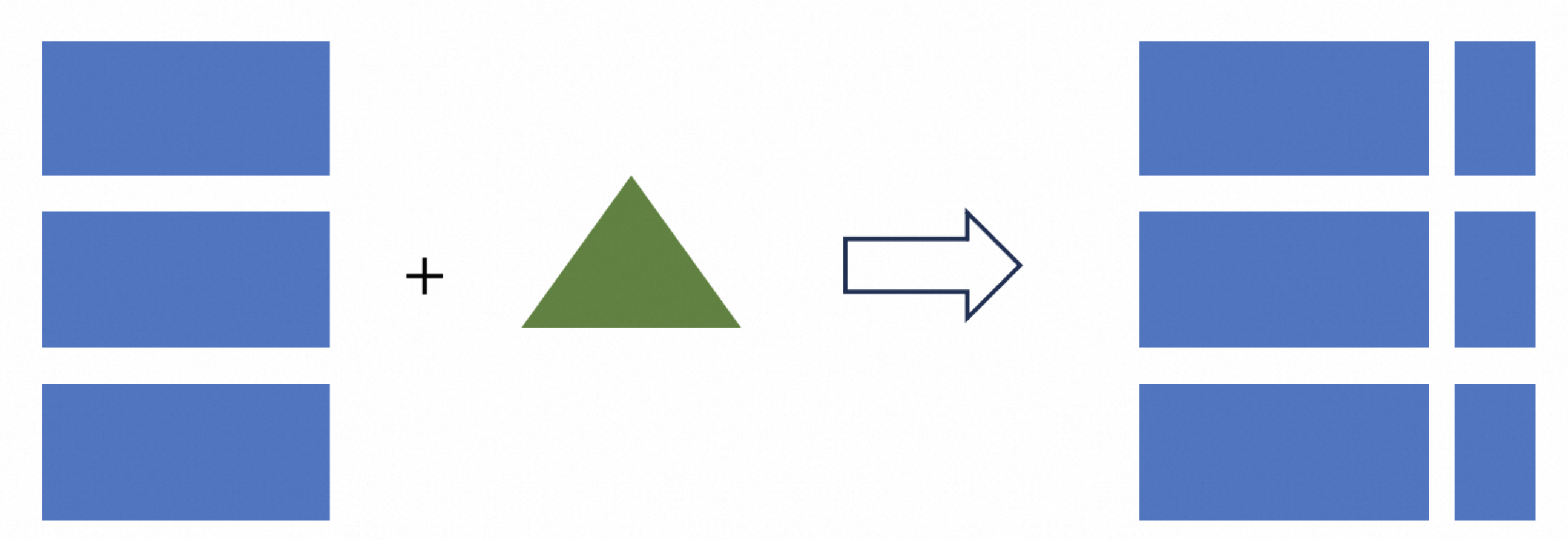
When the mode is MOR, it is necessary to merge all files for reading, as all files are ordered and undergo multi way merging, which includes a comparison calculation of the primary key.
There is an obvious issue here, where a single LSM tree can only have a single thread to read, so the read parallelism is limited. If the amount of data in the bucket is too large, it can lead to poor read performance. So in order to read performance, it is recommended to analyze the query requirements table and set the data volume in the bucket to be between 200MB and 1GB. But if the bucket is too small, there will be a lot of small file reads and writes, causing pressure on the file system.
In addition, due to the merging process, Filter based data skipping cannot be performed on non primary key columns, otherwise new data will be filtered out, resulting in incorrect old data.
- Write performance: very good.
- Read performance: not so good.
Copy On Write
ALTER TABLE orders SET ('full-compaction.delta-commits' = '1');
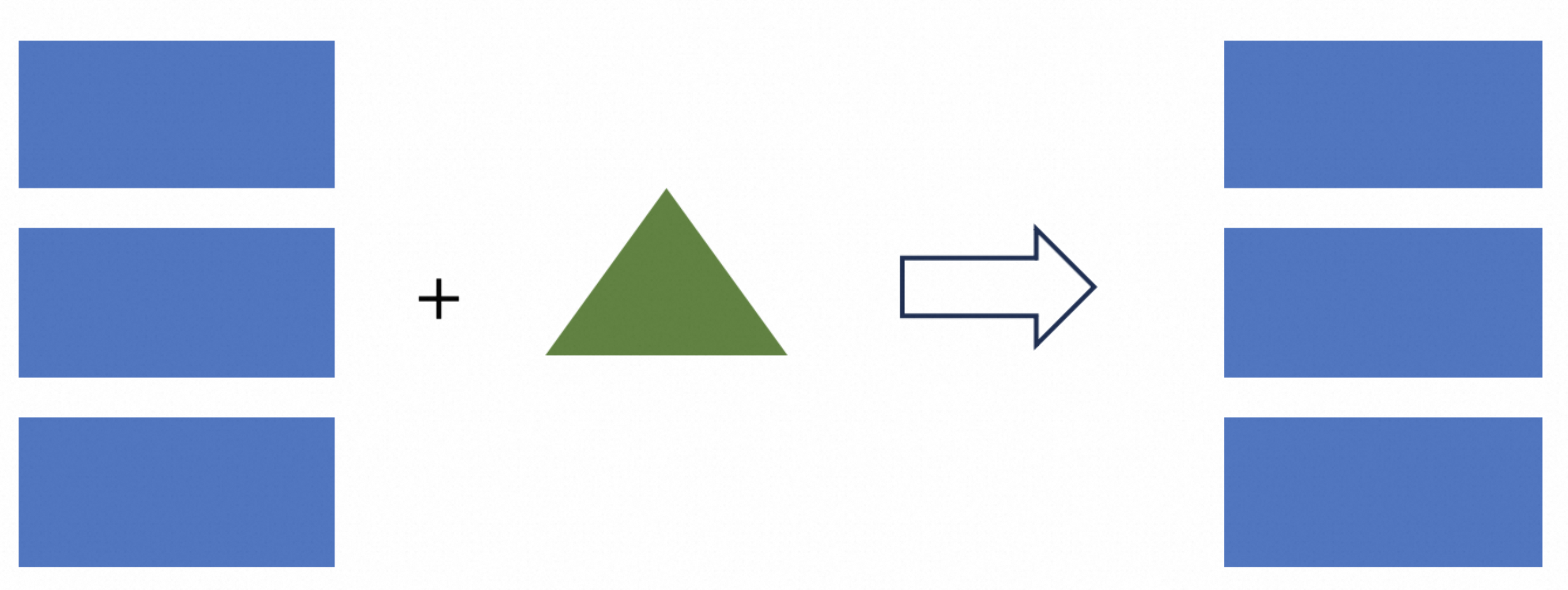
Set full-compaction.delta-commits to 1, which means that every write will be fully merged, and all data will be merged
to the highest level. When reading, merging is not necessary at this time, and the reading performance is the highest.
But every write requires full merging, and write amplification is very severe.
- Write performance: very bad.
- Read performance: very good.
Merge On Write
ALTER TABLE orders SET ('deletion-vectors.enabled' = 'true');
Thanks to Paimon's LSM structure, it has the ability to be queried by primary key. We can generate deletion vectors files when writing, representing which data in the file has been deleted. This directly filters out unnecessary rows during reading, which is equivalent to merging and does not affect reading performance.
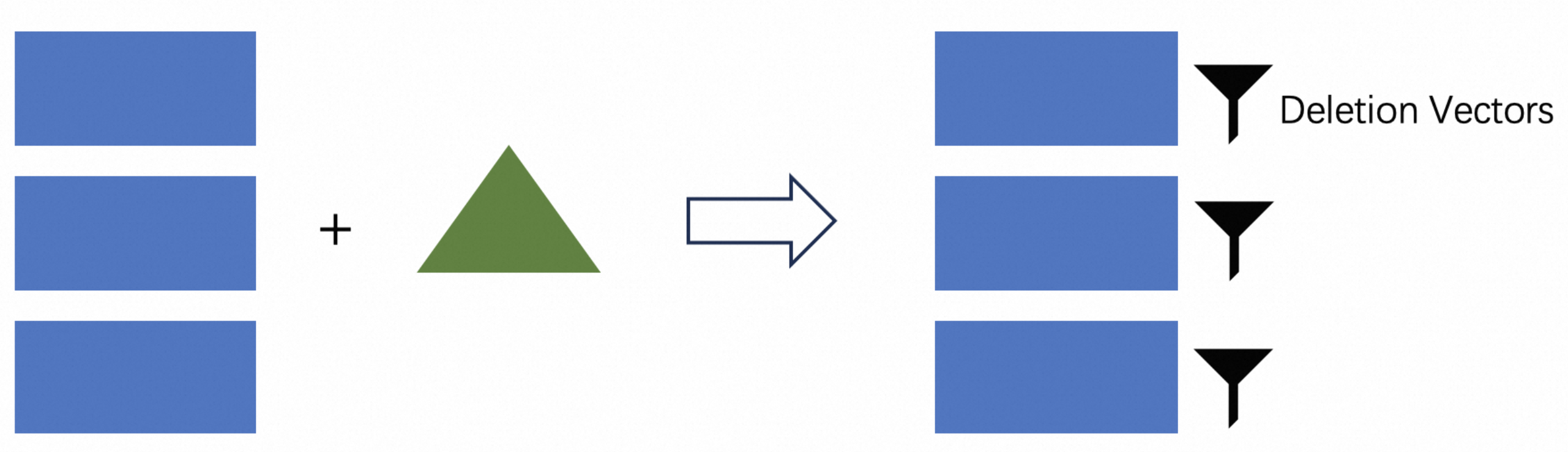
A simple example just like:
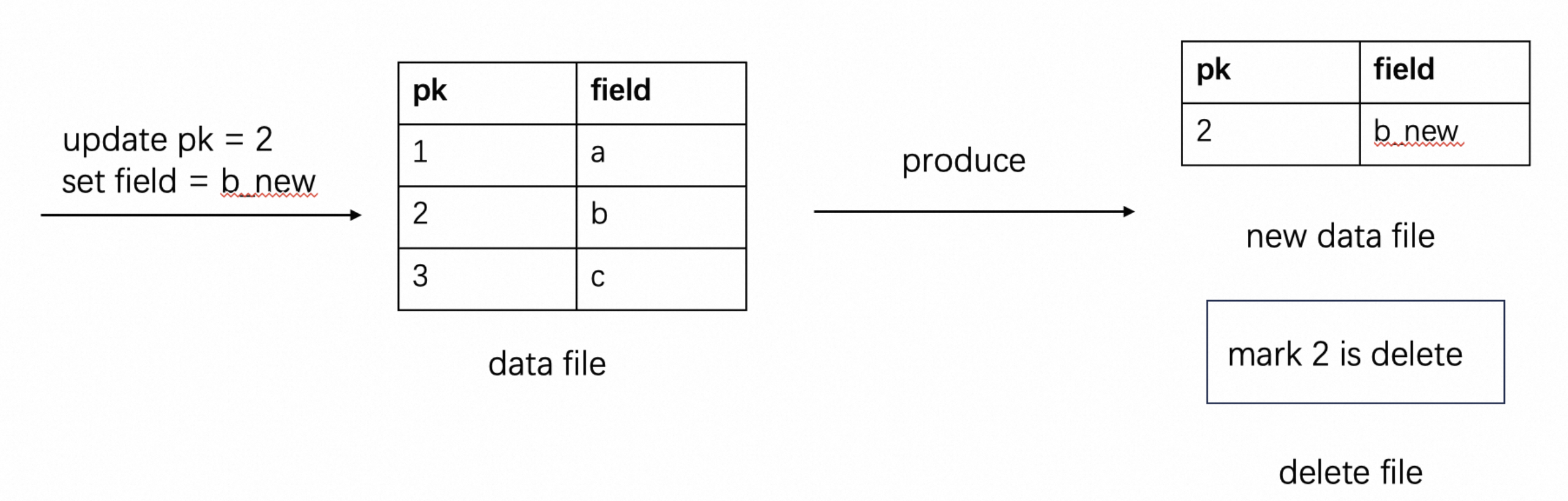
Updates data by deleting old record first and then adding new one.
- Write performance: good.
- Read performance: good.
Visibility guarantee: Tables in deletion vectors mode, the files with level 0 will only be visible after compaction. So by default, compaction is synchronous, and if asynchronous is turned on, there may be delays in the data.
MOR Read Optimized
If you don't want to use Deletion Vectors mode, you want to query fast enough in MOR mode, but can only find older data, you can also:
- Configure 'compaction.optimization-interval' when writing data.
- Query from read-optimized system table. Reading from results of optimized files avoids merging records with the same key, thus improving reading performance.
You can flexibly balance query performance and data latency when reading.