This documentation is for an unreleased version of Apache Paimon. We recommend you use the latest stable version.
Understand Files
Understand Files #
This article is specifically designed to clarify the impact that various file operations have on files.
This page provides concrete examples and practical tips for effectively managing them. Furthermore, through an in-depth exploration of operations such as commit and compact, we aim to offer insights into the creation and updates of files.
Prerequisite #
Before delving further into this page, please ensure that you have read through the following sections:
- Basic Concepts,
- Primary Key Table and Append Table
- How to use Paimon in Flink.
Understand File Operations #
Create Catalog #
Start Flink SQL client via ./sql-client.sh and execute the following
statements one by one to create a Paimon catalog.
CREATE CATALOG paimon WITH (
'type' = 'paimon',
'warehouse' = 'file:///tmp/paimon'
);
USE CATALOG paimon;
This will only create a directory at given path file:///tmp/paimon.
Create Table #
Execute the following create table statement will create a Paimon table with 3 fields:
CREATE TABLE T (
id BIGINT,
a INT,
b STRING,
dt STRING COMMENT 'timestamp string in format yyyyMMdd',
PRIMARY KEY(id, dt) NOT ENFORCED
) PARTITIONED BY (dt);
This will create Paimon table T under the path /tmp/paimon/default.db/T,
with its schema stored in /tmp/paimon/default.db/T/schema/schema-0
Insert Records Into Table #
Run the following insert statement in Flink SQL:
INSERT INTO T VALUES (1, 10001, 'varchar00001', '20230501');
Once the Flink job is completed, the records are written to the Paimon table through a successful commit.
Users can verify the visibility of these records by executing the query SELECT * FROM T which will return a single row.
The commit process creates a snapshot located at the path /tmp/paimon/default.db/T/snapshot/snapshot-1.
The resulting file layout at snapshot-1 is as described below:

The content of snapshot-1 contains metadata of the snapshot, such as manifest list and schema id:
{
"version" : 3,
"id" : 1,
"schemaId" : 0,
"baseManifestList" : "manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-0",
"deltaManifestList" : "manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-1",
"changelogManifestList" : null,
"commitUser" : "7d758485-981d-4b1a-a0c6-d34c3eb254bf",
"commitIdentifier" : 9223372036854775807,
"commitKind" : "APPEND",
"timeMillis" : 1684155393354,
"logOffsets" : { },
"totalRecordCount" : 1,
"deltaRecordCount" : 1,
"changelogRecordCount" : 0,
"watermark" : -9223372036854775808
}
Remind that a manifest list contains all changes of the snapshot, baseManifestList is the base
file upon which the changes in deltaManifestList is applied.
The first commit will result in 1 manifest file, and 2 manifest lists are
created (the file names might differ from those in your experiment):
./T/manifest:
manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-1
manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-0
manifest-2b833ea4-d7dc-4de0-ae0d-ad76eced75cc-0
manifest-2b833ea4-d7dc-4de0-ae0d-ad76eced75cc-0 is the manifest
file (manifest-1-0 in the above graph), which stores the information about the data files in the snapshot.
manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-0 is the
baseManifestList (manifest-list-1-base in the above graph), which is effectively empty.
manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-1 is the
deltaManifestList (manifest-list-1-delta in the above graph), which
contains a list of manifest entries that perform operations on data
files, which, in this case, is manifest-1-0.
Now let’s insert a batch of records across different partitions and see what happens. In Flink SQL, execute the following statement:
INSERT INTO T VALUES
(2, 10002, 'varchar00002', '20230502'),
(3, 10003, 'varchar00003', '20230503'),
(4, 10004, 'varchar00004', '20230504'),
(5, 10005, 'varchar00005', '20230505'),
(6, 10006, 'varchar00006', '20230506'),
(7, 10007, 'varchar00007', '20230507'),
(8, 10008, 'varchar00008', '20230508'),
(9, 10009, 'varchar00009', '20230509'),
(10, 10010, 'varchar00010', '20230510');
The second commit takes place and executing SELECT * FROM T will return
10 rows. A new snapshot, namely snapshot-2, is created and gives us the
following physical file layout:
% ls -1tR .
./T:
dt=20230501
dt=20230502
dt=20230503
dt=20230504
dt=20230505
dt=20230506
dt=20230507
dt=20230508
dt=20230509
dt=20230510
snapshot
schema
manifest
./T/snapshot:
LATEST
snapshot-2
EARLIEST
snapshot-1
./T/manifest:
manifest-list-9ac2-5e79-4978-a3bc-86c25f1a303f-1 # delta manifest list for snapshot-2
manifest-list-9ac2-5e79-4978-a3bc-86c25f1a303f-0 # base manifest list for snapshot-2
manifest-f1267033-e246-4470-a54c-5c27fdbdd074-0 # manifest file for snapshot-2
manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-1 # delta manifest list for snapshot-1
manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-0 # base manifest list for snapshot-1
manifest-2b833ea4-d7dc-4de0-ae0d-ad76eced75cc-0 # manifest file for snapshot-1
./T/dt=20230501/bucket-0:
data-b75b7381-7c8b-430f-b7e5-a204cb65843c-0.orc
...
# each partition has the data written to bucket-0
...
./T/schema:
schema-0
The new file layout as of snapshot-2 looks like

Delete Records From Table #
Now let’s delete records that meet the condition dt>=20230503.
In Flink SQL, execute the following statement:
DELETE FROM T WHERE dt >= '20230503';
The third commit takes place and it gives us snapshot-3. Now, listing the files
under the table and your will find out no partition is dropped. Instead, a new data
file is created for partition 20230503 to 20230510:
./T/dt=20230510/bucket-0:
data-b93f468c-b56f-4a93-adc4-b250b3aa3462-0.orc # newer data file created by the delete statement
data-0fcacc70-a0cb-4976-8c88-73e92769a762-0.orc # older data file created by the insert statement
This make sense since we insert a record in the second commit (represented by
+I[10, 10010, 'varchar00010', '20230510']) and then delete
the record in the third commit. Executing SELECT * FROM T will return 2 rows, namely:
+I[1, 10001, 'varchar00001', '20230501']
+I[2, 10002, 'varchar00002', '20230502']
The new file layout as of snapshot-3 looks like

Note that manifest-3-0 contains 8 manifest entries of ADD operation type,
corresponding to 8 newly written data files.
Compact Table #
As you may have noticed, the number of small files will augment over successive snapshots, which may lead to decreased read performance. Therefore, a full-compaction is needed in order to reduce the number of small files.
Let’s trigger the full-compaction now, and run a dedicated compaction job through flink run:
CALL sys.compact(
`table` => 'database_name.table_name',
partitions => 'partition_name',
order_strategy => 'order_strategy',
order_by => 'order_by',
options => 'paimon_table_dynamic_conf'
);
<FLINK_HOME>/bin/flink run \
-D execution.runtime-mode=batch \
/path/to/paimon-flink-action-1.4-SNAPSHOT.jar \
compact \
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
[--partition <partition-name>] \
[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \
[--table_conf <paimon-table-dynamic-conf> [--table_conf <paimon-table-dynamic-conf>] ...]
an example would be (suppose you’re already in Flink home)
CALL sys.compact('T');
./bin/flink run \
./lib/paimon-flink-action-1.4-SNAPSHOT.jar \
compact \
--path file:///tmp/paimon/default.db/T
All current table files will be compacted and a new snapshot, namely snapshot-4, is
made and contains the following information:
{
"version" : 3,
"id" : 4,
"schemaId" : 0,
"baseManifestList" : "manifest-list-9be16-82e7-4941-8b0a-7ce1c1d0fa6d-0",
"deltaManifestList" : "manifest-list-9be16-82e7-4941-8b0a-7ce1c1d0fa6d-1",
"changelogManifestList" : null,
"commitUser" : "a3d951d5-aa0e-4071-a5d4-4c72a4233d48",
"commitIdentifier" : 9223372036854775807,
"commitKind" : "COMPACT",
"timeMillis" : 1684163217960,
"logOffsets" : { },
"totalRecordCount" : 2,
"deltaRecordCount" : -16,
"changelogRecordCount" : 0,
"watermark" : -9223372036854775808
}
The new file layout as of snapshot-4 looks like

Note that manifest-4-0 contains 20 manifest entries (18 DELETE operations and 2 ADD operations)
- For partition
20230503to20230510, twoDELETEoperations for two data files - For partition
20230501to20230502, oneDELETEoperation and oneADDoperation for the same data file. This is because there has been an upgrade of the file from level 0 to the highest level. Please rest assured that this is only a change in metadata, and the file is still the same.
Alter Table #
Execute the following statement to configure full-compaction:
ALTER TABLE T SET ('full-compaction.delta-commits' = '1');
It will create a new schema for Paimon table, namely schema-1, but no snapshot
has actually used this schema yet until the next commit.
Expire Snapshots #
Remind that the marked data files are not truly deleted until the snapshot expires and no consumer depends on the snapshot. For more information, see Expiring Snapshots.
During the process of snapshot expiration, the range of snapshots is initially determined, and then data files within these snapshots are marked for deletion.
A data file is marked for deletion only when there is a manifest entry of kind DELETE that references that specific data file.
This marking ensures that the file will not be utilized by subsequent snapshots and can be safely removed.
Let’s say all 4 snapshots in the above diagram are about to expire. The expire process is as follows:
-
It first deletes all marked data files, and records any changed buckets.
-
It then deletes any changelog files and associated manifests.
-
Finally, it deletes the snapshots themselves and writes the earliest hint file.
If any directories are left empty after the deletion process, they will be deleted as well.
Let’s say another snapshot, snapshot-5 is created and snapshot expiration is triggered. snapshot-1 to snapshot-4 are
to be deleted. For simplicity, we will only focus on files from previous snapshots, the final layout after snapshot
expiration looks like:

As a result, partition 20230503 to 20230510 are physically deleted.
Flink Stream Write #
Finally, we will examine Flink Stream Write by utilizing the example of CDC ingestion. This section will address the capturing and writing of change data into Paimon, as well as the mechanisms behind asynchronous compact and snapshot commit and expiration.
To begin, let’s take a closer look at the CDC ingestion workflow and the unique roles played by each component involved.

MySQL CDC Sourceuniformly reads snapshot and incremental data, withSnapshotReaderreading snapshot data andBinlogReaderreading incremental data, respectively.Paimon Sinkwrites data into Paimon table in bucket level. TheCompactManagerwithin it will trigger compaction asynchronously.Committer Operatoris a singleton responsible for committing and expiring snapshots.
Next, we will go over end-to-end data flow.

MySQL Cdc Source read snapshot and incremental data and emit them to downstream after normalization.

Paimon Sink first buffers new records in a heap-based LSM tree, and flushes them to disk when
the memory buffer is full. Note that each data file written is a sorted run. At this point, no manifest file and snapshot
is created. Right before Flink checkpoint takes places, Paimon Sink will flush all buffered records and send committable message
to downstream, which is read and committed by Committer Operator during checkpoint.

During checkpoint, Committer Operator will create a new snapshot and associate it with manifest lists so that the snapshot
contains information about all data files in the table.

At later point asynchronous compaction might take place, and the committable produced by CompactManager contains information
about previous files and merged files so that Committer Operator can construct corresponding manifest entries. In this case
Committer Operator might produce two snapshot during Flink checkpoint, one for data written (snapshot of kind Append) and the
other for compact (snapshot of kind Compact). If no data file is written during checkpoint interval, only snapshot of kind Compact
will be created. Committer Operator will check against snapshot expiration and perform
physical deletion of marked data files.
Understand Small Files #
Many users are concerned about small files, which can lead to:
- Stability issue: Too many small files in HDFS, NameNode will be overstressed.
- Cost issue: A small file in HDFS will temporarily use the size of a minimum of one Block, for example 128 MB.
- Query efficiency: The efficiency of querying too many small files will be affected.
Understand Checkpoints #
Assuming you are using Flink Writer, each checkpoint generates 1-2 snapshots, and the checkpoint forces the files to be generated on DFS, so the smaller the checkpoint interval the more small files will be generated.
- So first thing is increase checkpoint interval.
By default, not only checkpoint will cause the file to be generated, but writer’s memory (write-buffer-size) exhaustion
will also flush data to DFS and generate the corresponding file. You can enable write-buffer-spillable to generate
spilled files in writer to generate bigger files in DFS.
- So second thing is increase
write-buffer-sizeor enablewrite-buffer-spillable.
Understand Snapshots #
Paimon maintains multiple versions of files, compaction and deletion of files are logical and do not actually delete files. Files are only really deleted when Snapshot is expired, so the first way to reduce files is to reduce the time it takes for snapshot to be expired. Flink writer will automatically expire snapshots.
See Expire Snapshots.
Understand Partitions and Buckets #
Paimon files are organized in a layered style. The following image illustrates the file layout. Starting from a snapshot file, Paimon readers can recursively access all records from the table.
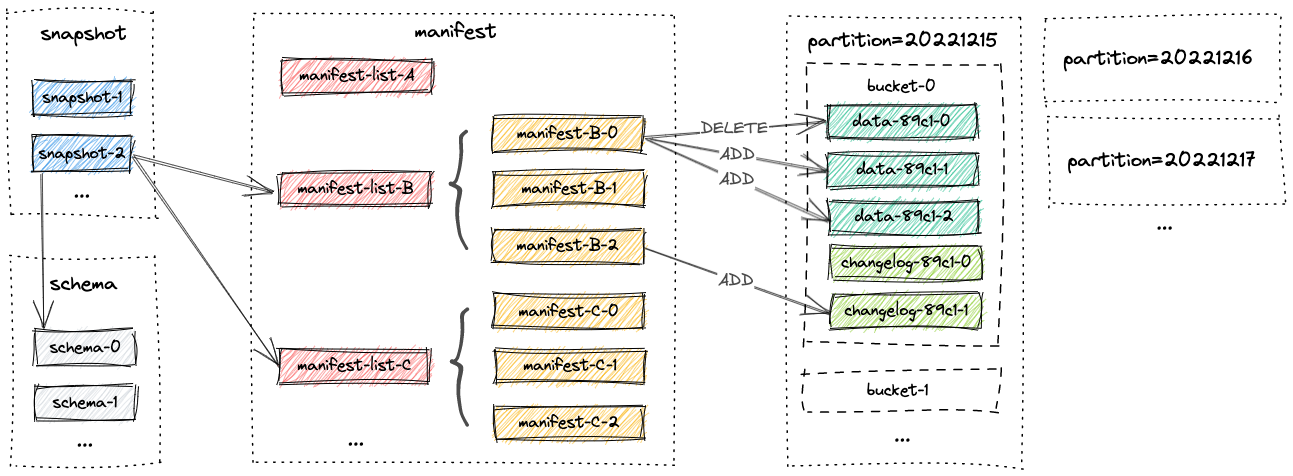
For example, the following table:
CREATE TABLE MyTable (
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh) WITH (
'bucket' = '10'
);
The table data will be physically sliced into different partitions, and different buckets inside, so if the overall data volume is too small, there is at least one file in a single bucket, I suggest you configure a smaller number of buckets, otherwise there will be quite a few small files as well.
Understand LSM for Primary Table #
LSM tree organizes files into several sorted runs. A sorted run consists of one or multiple data files and each data file belongs to exactly one sorted run.

By default, sorted runs number depends on num-sorted-run.compaction-trigger, see Compaction for Primary Key Table,
this means that there are at least 5 files in a bucket. If you want to reduce this number, you can keep fewer files, but write performance may suffer.
Understand Files for Bucketed Append Table #
By default, Append also does automatic compaction to reduce the number of small files.
However, for Bucketed Append table, it will only compact the files within the Bucket for sequential purposes, which may keep more small files. See Bucketed Append.
Understand Full-Compaction #
Maybe you think the 5 files for the primary key table are actually okay, but the Append table (bucket) may have 50 small files in a single bucket, which is very difficult to accept. Worse still, partitions that are no longer active also keep so many small files.
Configure ‘full-compaction.delta-commits’ perform full-compaction periodically in Flink writing. And it can ensure that partitions are full compacted before writing ends.